Dataset Iris
#Python #Regressão #NumPy #MatPlotLib #Pandas #ScikitLearn #MachineLearning

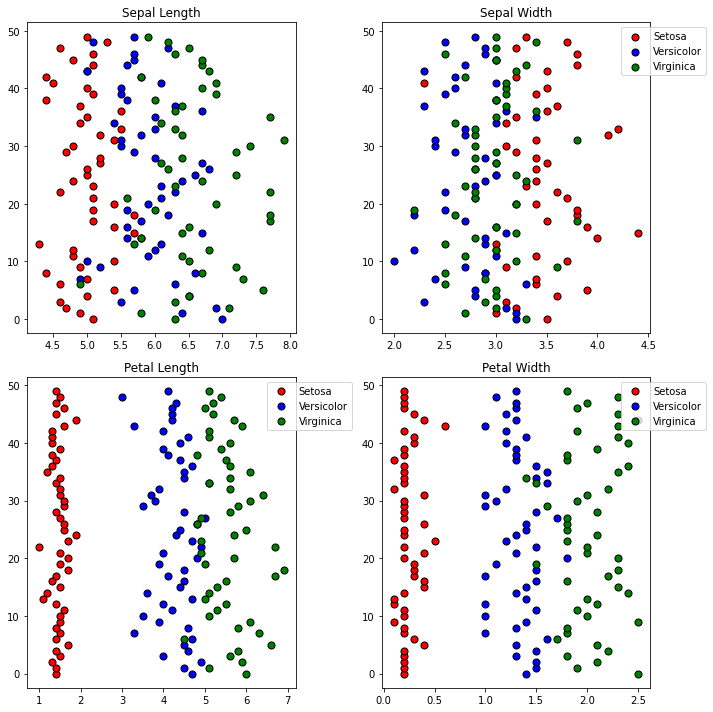
Nesse script em Python, trabalho com o clássico dataset Iris, que contém 150 dados, sendo 50 de cada tipo de planta (Setosa, Versicolor e Virgínica). Cada entrada tem 4 informações: Largura e Altura da pétala, e largura e altura da Sépala.
O programa tenta correlacionar esses dados e predizer qual dos tipos das plantas correspondem os dados de entrada.
O programa utiliza a biblioteca NumPy, para fazer os cálculos, MatPlotLib para mostrar os gráficos, Pandas para poder trabalhar com um dataframe e os algoritmos de Machine Learning do SciKitLearn, para fazer a regressão.
Analisando o gráfico notamos que os parâmetros da pétala e da sépala da Iris Setosa, não se misturam (note como os pontos em vermelho não se misturam com os outros, nos dois últimos gráficos) com a Versicolor e Virgínica, por esse motivo, o sistema foi treinado apenas com os dois últimos tipos de planta. Os dados foram separados em 80% para treinamento e 20% para teste. Nesse experimento foi usado os seguintes algoritmos:
- Regressão Logística.
- Regressão Linear.
- Árvore de Decisão.
- Vizinhos Próximos KNN.
- Classificador Floresta Aleatória.
- Support Vector Machine (SVM).
- Linear Discriminant Analysis (LDA).
Nesse experimento a métrica utilizada para validar os algoritmos foi a acurácia, sendo que os algoritmos: Regressão Linear, LDA, Árvore de Decisão, SVM e Floresta Aleatória tiveram 100% de acurácia.